
Dynamic Provider Discovery with Python Introspection
Crossplane Python Functions | Part 5
Building a production multi-cloud platform with Python
In Part 4, we saw how add_definition() magically finds and loads the right cloud implementation. But how does it actually work?
This post demystifies the Python introspection behind automatic provider discovery. You'll understand inspect, importlib, and when to extend these patterns for your own use cases.
The Problem: Hard-Coding Doesn't Scale
You could explicitly route to cloud implementations:
def add_bucket(**r):
if r["composition"].cloud == "gcp":
from .gcp.bucket import add_bucket as gcp_add_bucket
return gcp_add_bucket(**r)
elif r["composition"].cloud == "aws":
from .aws.bucket import add_bucket as aws_add_bucket
return aws_add_bucket(**r)
elif r["composition"].cloud == "azure":
from .azure.bucket import add_bucket as azure_add_bucket
return azure_add_bucket(**r)
Problems:
- Every agnostic function repeats this pattern
- Adding a cloud means editing every agnostic function
- Typos in import paths cause runtime errors
- Hard to test the routing logic
We need a system that automatically discovers implementations based on conventions.
Python's inspect Module
The inspect module lets Python programs examine their own call stack, function signatures, and module structure.
Examining the Call Stack
import inspect
def outer_function():
inner_function()
def inner_function():
stack = inspect.stack()
for frame_info in stack:
print(f"Function: {frame_info.function}")
print(f"File: {frame_info.filename}")
print(f"Line: {frame_info.lineno}")
print("---")
outer_function()
Output:
Function: inner_function
File: example.py
Line: 7
---
Function: outer_function
File: example.py
Line: 4
---
Function: <module>
File: example.py
Line: 13
Getting Caller Information
add_definition() uses this to find what called it:
import inspect
def add_definition(definition, **r):
# Get the call stack
stack = inspect.stack()
# stack[0] is this function (add_definition)
# stack[1] is the function that called us
parentframe = stack[1][0]
# Get the module containing the caller
module_obj = inspect.getmodule(parentframe)
module_name = module_obj.__name__
# Get the function name that called us
function_name = parentframe.f_code.co_name
print(f"Called from: {module_name}.{function_name}")
When myplatform.resources.bucket.add_bucket() calls add_definition():
Called from: myplatform.resources.bucket.add_bucket
Extracting Module Path Components
We need to transform the caller's module path into a cloud-specific path:
# Caller module: "myplatform.resources.bucket"
# We want: "myplatform.resources.{cloud}.bucket"
module_name = "myplatform.resources.bucket"
package, module = module_name.rsplit(".", 1)
# package = "myplatform.resources"
# module = "bucket"
cloud = "gcp"
cloud_module = f"{package}.{cloud}.{module}"
# "myplatform.resources.gcp.bucket"
The rsplit(".", 1) splits from the right, once, giving us the package path and leaf module name.
Dynamic Module Loading with importlib
Python's importlib module loads modules at runtime:
import importlib
# Load a module by string path
module = importlib.import_module("myplatform.resources.gcp.bucket")
# Get a function from that module
add_bucket_func = getattr(module, "add_bucket")
# Call it
result = add_bucket_func(force_destroy=True, r=resource)
Handling Missing Implementations
Not every cloud has every resource. Use try/except:
try:
provider = importlib.import_module(f"{package}.{cloud}.{module}")
provider_func = getattr(provider, function_name)
definition = merge(definition, provider_func(*args, r))
except ModuleNotFoundError:
# Cloud doesn't implement this resource
# Use the agnostic definition as-is
pass
except AttributeError:
# Module exists but function doesn't
pass
The Complete add_definition() Implementation
Here's the full implementation with comments:
import importlib
import inspect
import yaml
from deepmerge import always_merger
def add_definition(definition: dict | str, *args, **r: Unpack[ResourceDict]):
"""Add a managed resource definition to the composition.
Combines cloud-agnostic and cloud-specific definitions automatically.
"""
# Wrap kwargs in Resource object for dot notation access
r = Resource(**r)
# Accept YAML strings or dicts
if isinstance(definition, str):
definition = yaml.safe_load(definition)
# === INTROSPECTION MAGIC ===
# Get the call stack
stack = inspect.stack()
# Get the frame of our caller (index 1)
# stack[0] = add_definition (this function)
# stack[1] = add_bucket (caller we want)
parentframe = stack[1][0]
# Get the caller's module path
# e.g., "myplatform.resources.bucket"
caller_module = inspect.getmodule(parentframe)
full_module_path = caller_module.__name__
# Split into package and leaf module
# "myplatform.resources" and "bucket"
package, module = full_module_path.rsplit(".", 1)
# Get the caller's function name
# e.g., "add_bucket"
function_name = parentframe.f_code.co_name
# Get the cloud from the resource
cloud = r.cloud # e.g., "gcp"
# === DYNAMIC LOADING ===
try:
# Import "myplatform.resources.gcp.bucket"
provider = importlib.import_module(f"{package}.{cloud}.{module}")
# Get add_bucket from that module
provider_func = getattr(provider, function_name)
# Call it and merge results
cloud_definition = provider_func(*args, r)
definition = always_merger.merge(definition, cloud_definition)
# Check for _extra function
# e.g., add_bucket_extra for post-processing
extra_func_name = f"{function_name}_extra"
if extra_func := getattr(provider, extra_func_name, None):
extra_func(*args, r)
except ModuleNotFoundError:
# Cloud doesn't have this resource type
# Use agnostic definition only
pass
# Add to composition output
add_composed(r, definition)
# Set up usage relationships
set_usage(r, definition)
# Handle explicit dependencies
for u in r.uses:
if u:
add_usage(r.composition, of=u, by=r.name)
Understanding the Call Flow
Let's trace a complete call:
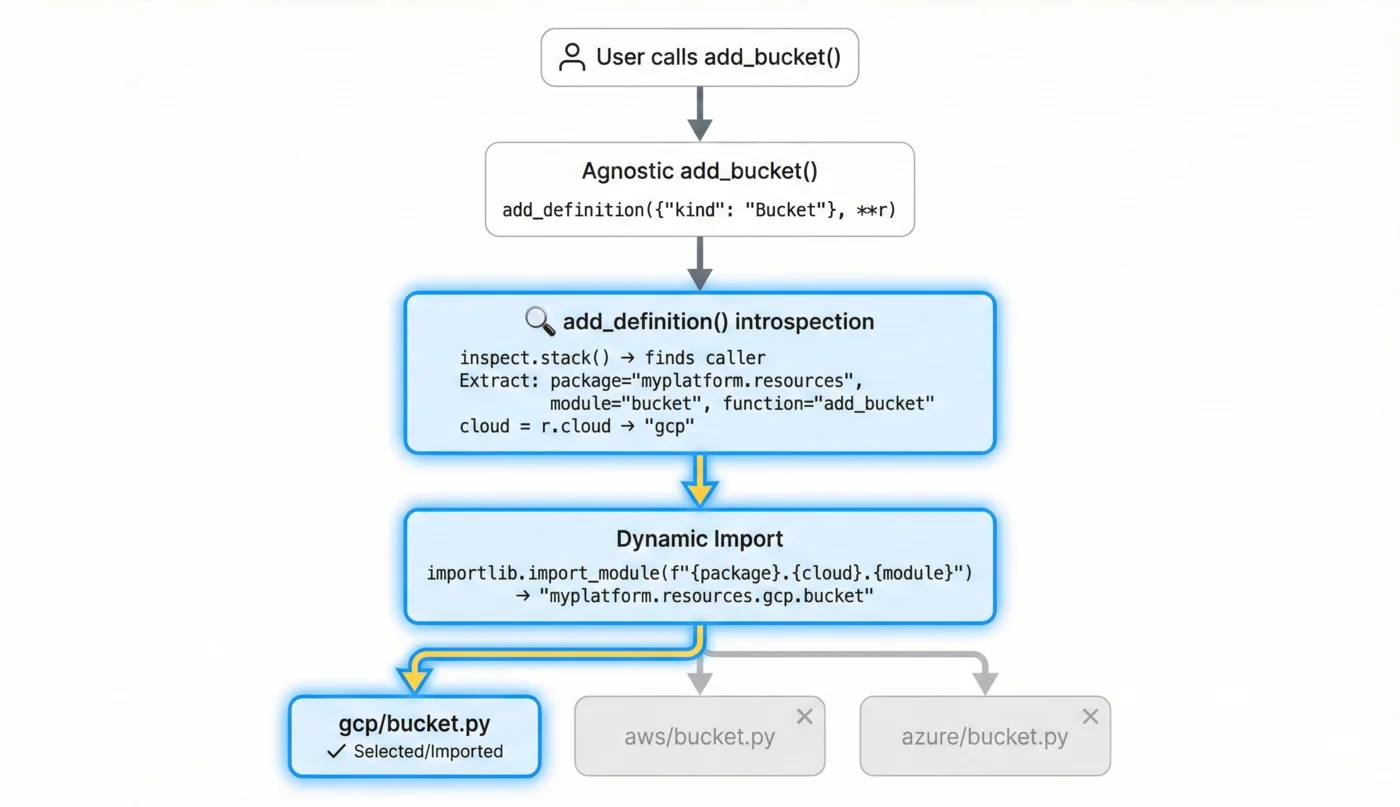
1. User Calls add_bucket
# In function/cluster/cluster.py
myplatform.add_bucket(
composition=c,
name="state-bucket",
external_name=f"{c.cluster_name}-state",
force_destroy=True,
)
2. Agnostic add_bucket is Called
# In myplatform/resources/bucket.py
def add_bucket(force_destroy: bool, **r: Unpack[ResourceDict]):
definition = {"kind": "Bucket"}
add_definition(definition, force_destroy, **r)
3. add_definition Introspects
# Inside add_definition:
stack = inspect.stack()
parentframe = stack[1][0]
# parentframe is the add_bucket frame in myplatform/resources/bucket.py
module = inspect.getmodule(parentframe)
# module.__name__ = "myplatform.resources.bucket"
package, module_name = "myplatform.resources.bucket".rsplit(".", 1)
# package = "myplatform.resources"
# module_name = "bucket"
function_name = parentframe.f_code.co_name
# function_name = "add_bucket"
cloud = r.cloud # "gcp"
4. Cloud Module is Loaded
provider = importlib.import_module("myplatform.resources.gcp.bucket")
provider_func = getattr(provider, "add_bucket")
# This is the GCP add_bucket function
cloud_definition = provider_func(force_destroy, r)
# Returns {"apiVersion": "storage.gcp.upbound.io/v1beta2", ...}
5. Definitions are Merged
# agnostic: {"kind": "Bucket"}
# cloud: {"apiVersion": "storage.gcp...", "spec": {...}}
# merged: {"kind": "Bucket", "apiVersion": "storage.gcp...", "spec": {...}}
The _extra() Pattern in Detail
Post-processing functions follow a naming convention:
# Main function
def add_cluster(r: Resource):
return {...}
# Extra function (optional)
def add_cluster_extra(r: Resource):
# Called automatically after add_cluster
add_related_resource(r)
Why _extra() Instead of Adding to Main Function?
- Separation of concerns: Main function returns definition, extra function handles side effects
- Optional by cloud: GCP might not need extra processing
- Testable independently: Test main definition separate from extras
- Clear ordering: Extras always run after merge
Real Example: AWS ClusterAuth
AWS EKS requires a separate ClusterAuth resource:
# myplatform/resources/aws/cluster.py
def add_cluster(r: Resource):
"""Returns the EKS Cluster definition."""
return {
"apiVersion": "eks.aws.upbound.io/v1beta1",
}
def add_cluster_extra(r: Resource):
"""Add AWS-specific resources after the cluster."""
# Create ClusterAuth for kubeconfig export
cluster_auth = {
"apiVersion": "eks.aws.upbound.io/v1beta1",
"kind": "ClusterAuth",
"spec": {
"forProvider": {
"region": r.template["spec"]["forProvider"]["region"],
"clusterName": r.external_name,
},
"writeConnectionSecretToRef": {
"namespace": r.composition.ns,
"name": r.external_name,
},
},
}
# Add directly to composition output
update_response(r.composition, "cluster_auth", cluster_auth)
# Ensure proper deletion order
add_usage(r.composition, of="cluster_auth", by=r.name)
GCP doesn't have an add_cluster_extra() because GKE doesn't need ClusterAuth.
Extending the Pattern
Custom Resource Discovery
You might want different discovery logic. Create your own:
def add_definition_with_version(
definition: dict,
version: str,
**r: Unpack[ResourceDict]
):
"""Load implementation based on API version, not just cloud."""
r = Resource(**r)
stack = inspect.stack()
parentframe = stack[1][0]
module_obj = inspect.getmodule(parentframe)
package, module = module_obj.__name__.rsplit(".", 1)
function_name = parentframe.f_code.co_name
# Use version directory instead of cloud
# e.g., myplatform.resources.v1.bucket
try:
provider = importlib.import_module(f"{package}.{version}.{module}")
provider_func = getattr(provider, function_name)
definition = always_merger.merge(definition, provider_func(r))
except ModuleNotFoundError:
pass
add_composed(r, definition)
Multiple Discovery Paths
Check multiple locations:
def find_implementation(package, cloud, module, function_name):
"""Try multiple paths to find an implementation."""
paths_to_try = [
f"{package}.{cloud}.{module}", # myplatform.resources.gcp.bucket
f"{package}.{cloud}.common", # myplatform.resources.gcp.common
f"{package}.providers.{cloud}.{module}", # myplatform.resources.providers.gcp.bucket
]
for path in paths_to_try:
try:
provider = importlib.import_module(path)
if hasattr(provider, function_name):
return getattr(provider, function_name)
except ModuleNotFoundError:
continue
return None
Registry-Based Discovery
For complex systems, use a registry:
# Resource registry
_IMPLEMENTATIONS = {}
def register_implementation(cloud: str, resource: str):
"""Decorator to register implementations."""
def decorator(func):
key = (cloud, resource)
_IMPLEMENTATIONS[key] = func
return func
return decorator
def get_implementation(cloud: str, resource: str):
"""Look up registered implementation."""
return _IMPLEMENTATIONS.get((cloud, resource))
# Usage
@register_implementation("gcp", "bucket")
def gcp_add_bucket(r: Resource):
return {...}
@register_implementation("aws", "bucket")
def aws_add_bucket(r: Resource):
return {...}
Debugging Introspection
Print the Call Chain
def debug_call_chain():
"""Print the current call stack."""
stack = inspect.stack()
for i, frame_info in enumerate(stack):
module = inspect.getmodule(frame_info[0])
module_name = module.__name__ if module else "<unknown>"
print(f"[{i}] {module_name}.{frame_info.function}")
Log Dynamic Imports
def add_definition(definition, *args, **r):
r = Resource(**r)
stack = inspect.stack()
parentframe = stack[1][0]
package, module = inspect.getmodule(parentframe).__name__.rsplit(".", 1)
function_name = parentframe.f_code.co_name
cloud = r.cloud
target_module = f"{package}.{cloud}.{module}"
r.composition.log.debug(
"Dynamic import attempt",
target=target_module,
function=function_name,
cloud=cloud,
)
try:
provider = importlib.import_module(target_module)
r.composition.log.debug("Module loaded successfully", module=target_module)
# ...
except ModuleNotFoundError as e:
r.composition.log.debug("Module not found", module=target_module, error=str(e))
Performance Considerations
Import Caching
Python caches imports in sys.modules. Repeated calls don't reload:
import sys
# First call: actually loads the module
importlib.import_module("myplatform.resources.gcp.bucket")
# Subsequent calls: returns cached module
"myplatform.resources.gcp.bucket" in sys.modules # True
Stack Inspection Cost
inspect.stack() is relatively expensive. For high-throughput scenarios, consider caching:
from functools import lru_cache
@lru_cache(maxsize=128)
def get_provider_func(package: str, cloud: str, module: str, func_name: str):
"""Cache provider function lookups."""
try:
provider = importlib.import_module(f"{package}.{cloud}.{module}")
return getattr(provider, func_name, None)
except ModuleNotFoundError:
return None
Key Takeaways
inspect.stack()lets you examine the call chain at runtimeinspect.getmodule()maps a frame to its source moduleimportlib.import_module()loads modules by string path- Convention-based discovery (
{package}.{cloud}.{module}) eliminates hard-coded routing - The
_extra()pattern handles cloud-specific post-processing - Always handle
ModuleNotFoundErrorfor missing implementations
Next Up
In Part 6, we'll explore EnvironmentConfigs—how to manage configuration across environments without hard-coding values in your compositions.
Written by Marouan Chakran, Senior SRE and Platform Engineer, building multi-cloud platforms with Crossplane and Python.
Part 5 of 10 | Previous: The 3-Layer Resource Pattern | Next: Configuration with EnvironmentConfigs
Companion repository: github.com/Marouan-chak/crossplane-python-blog-series
Tags: crossplane, platform-engineering, kubernetes, python, devops